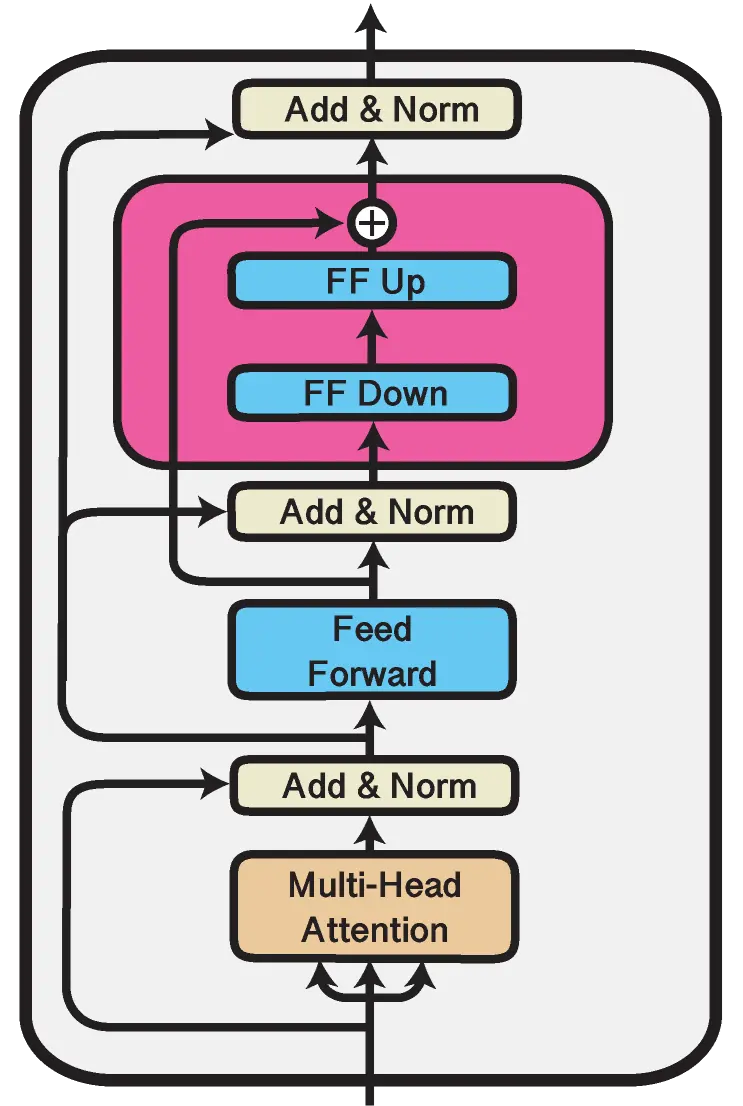
Adapter for fine tuning LLM
OSS
Creating a patch for integrating adapter modules into the RoBERTa model allows for efficient fine-tuning tailored to specific tasks. By embedding lightweight adapters within the pre-trained layers of RoBERTa, we can freeze the majority of the original parameters, updating only the new adapter parameters. This approach significantly reduces computational overhead and speeds up training. Implementing this patch involves defining the adapter architecture, integrating it within RoBERTa, and focusing the training on these adapters to leverage pre-existing knowledge effectively. Don't forget to check the source code!

