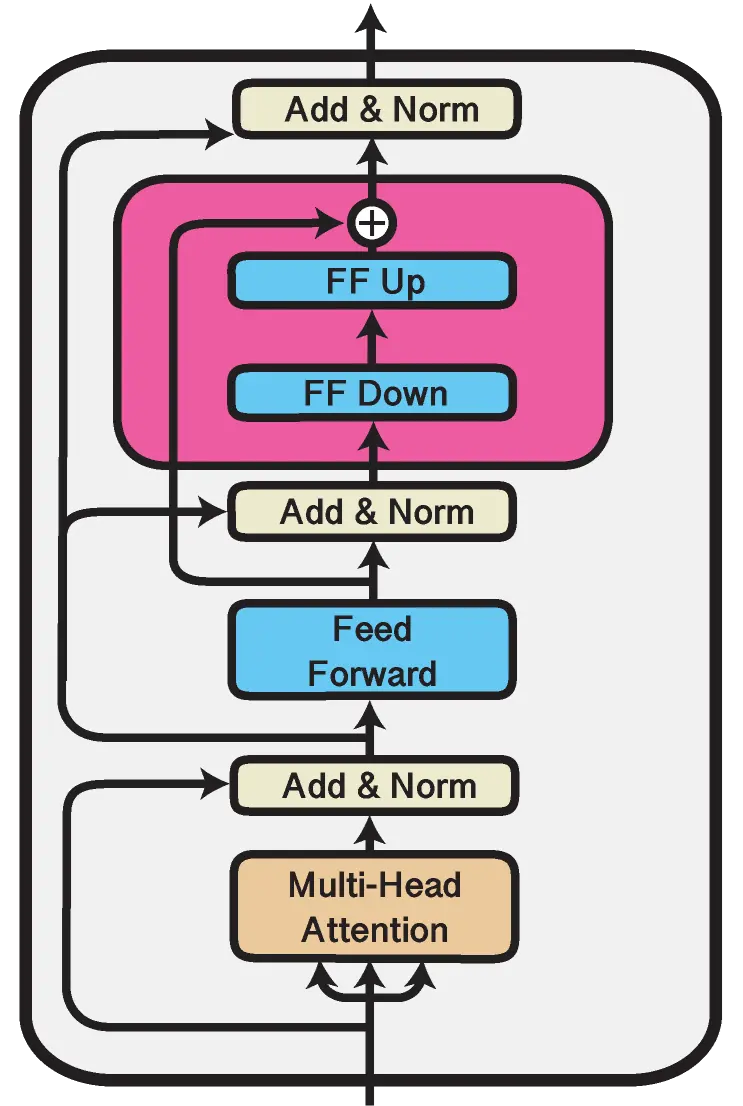
Adapter for fine tuning LLM
Access the project in: here
Adapter Modules: A Detailed Exploration
In the bustling realm of deep learning, particularly within the scope of natural language processing (NLP), adapter modules have emerged as game-changers. These ingenious tools offer a streamlined approach to fine-tuning pre-trained models for various downstream tasks, eliminating the need for exhaustive retraining. In this blog, we’ll dive deep into the essence of adapter modules, their advantages, and their seamless integration into transformer models, with a spotlight on the RobertaForSequenceClassification model.
What Are Adapter Modules?
Adapters are compact neural networks embedded within the layers of a pre-trained model. They enable the model to specialize in particular tasks while maintaining the majority of the original model parameters intact, thereby reducing computational demands and the volume of training data required.
Key Benefits
- Efficiency: Adapter modules drastically cut down the computational load for training.
- Flexibility: They facilitate the adaptation of a single model to multiple tasks with ease.
- Memory Saving: By introducing only a handful of additional parameters, adapters save memory compared to training an entire model from scratch.
Integration of Adapters in the Roberta Model
To grasp how adapters function, let’s explore their integration within the RobertaForSequenceClassification model. This section will break down the model’s core components and elucidate where adapters fit in:
Model Architecture
The RobertaForSequenceClassification model is based on the RoBERTa (Robustly optimized BERT approach) architecture, featuring several key components:
- Embeddings: Converts input tokens into dense vectors.
- Encoder: Processes these vectors through multiple layers of self-attention and feed-forward networks.
- Classifier Head: Maps the encoded representations to the desired output (e.g., class labels).
Example Code Structure (Conceptual Explanation Only)
Embedding Layer
- Converts words and positions into embeddings.
- Employs techniques like layer normalization and dropout.
Encoder Layer
- Comprises multiple sub-layers, including self-attention and feed-forward layers.
- Integrates adapters within the self-attention and output layers to tailor the network for specific tasks.
Classification Head
- Applies a dense layer followed by dropout for the final classification task.
Detailed Explanation
- Adapters in Self-Attention Layers: The self-attention mechanism is pivotal in learning the interrelations between words in a sentence. Adapters tweak the self-attention output to better align with specific tasks.
- Adapters in Output Layers: Output layers incorporate adapters to fine-tune the dense representation for the final output, allowing the model to harness pre-trained knowledge while adapting to new data.
Sample Adapter Integration
Although we’re not including executable code here, here’s a conceptual overview:
class Adapter(nn.Module):
def __init__(self, input_dim, adapter_dim):
super(Adapter, self).__init__()
self.linear1 = nn.Linear(input_dim, adapter_dim)
self.linear2 = nn.Linear(adapter_dim, input_dim)
def forward(self, x):
out = F.relu(self.linear1(x))
out = self.linear2(out)
return out + x # Residual connection
Freeze Base Model Parameters:
for name, param in model.named_parameters():
if 'adapter' in name:
param.requires_grad = True
else:
param.requires_grad = False
Practical Example: Sentiment Analysis with RoBERTa and Adapters
To put this into perspective, imagine fine-tuning a RoBERTa model for a sentiment analysis task:
-
Dataset Preparation Load and preprocess a dataset (e.g., IMDB reviews).
-
Model Preparation Insert adapters within the model architecture.
Freeze the parameters of the base model.
-
Training Train only the adapter parameters using a task-specific loss function (e.g., cross-entropy for classification tasks).
-
Evaluation Assess the model’s performance on a test dataset to ensure it has adapted to the new task effectively.
-
Data Preprocessing For sentiment analysis, you would typically preprocess the text data, tokenize it using a suitable tokenizer (like AutoTokenizer from Hugging Face), and then prepare it for training.
-
Adapter Training Once the data is ready, the training process focuses on updating the adapter parameters while keeping the rest of the model parameters frozen. This ensures that the model can leverage pre-trained knowledge while adapting efficiently to new tasks.
-
Conclusion Adapter modules provide an efficient and flexible approach to model fine-tuning. They help in leveraging the power of pre-trained models while significantly reducing the computational and data requirements. Inserting adapters in models like RobertaForSequenceClassification allows for effective adaptation to a wide range of downstream tasks, making them a powerful tool in the NLP toolkit.